AI大佬曼宁转赞,MetaGPT团队首提「Atom of Thoughts」
栏目:成功案例 发布时间:2025-03-16 09:26
AI年夜佬曼宁转赞,MetaGPT团队首提「Atom of Thoughts」,原子化思考让4o-mini暴打推理模子? AoT 作者团队来自 MetaGPT 开源社区。第一作者为喷鼻港科技年夜学(广州)的滕枫蔚,通信作者为 DeepWisdom 开创人兼 CEO 吴承霖。团队还包含 DeepWisdom 研讨员于兆洋、中国国民年夜学的石泉、喷鼻港科技年夜学(广州)的博士生张佳钇跟助理教学骆昱宇。
AoT 作者团队来自 MetaGPT 开源社区。第一作者为喷鼻港科技年夜学(广州)的滕枫蔚,通信作者为 DeepWisdom 开创人兼 CEO 吴承霖。团队还包含 DeepWisdom 研讨员于兆洋、中国国民年夜学的石泉、喷鼻港科技年夜学(广州)的博士生张佳钇跟助理教学骆昱宇。 论文题目:Atom of Thoughts for Markov LLM Test-Time Scaling论文地点:https://arxiv.org/abs/2502.12018名目地点:https://github.c188BET亚洲体育投注om/qixucen/atom从 “长链推理” 到 “原子头脑”:AoT 的出生年夜言语模子(LLM)比年来凭仗练习时扩大(train-time scaling)获得了明显机能晋升。但是,跟着模子范围跟数据量的瓶颈浮现,测试时扩大(test-time scaling)成为进一步开释潜力的新偏向。但是,无论是头脑链(CoT)、头脑树(ToT)等提醒战略跟推理框架,仍是 OpenAI o1/o3 跟 DeepSeek-R1 等推理模子,在推理时都适度依附完全汗青信息,招致盘算资本挥霍,同时冗余信息烦扰无效推理。详细来说,基于链的方式每停止一步推理,都需回想已有的完全链条;基于树的方式则须要追踪先人跟同层节点;基于图的方式容许节点恣意衔接,进一步减轻了汗青信息依附,招致盘算庞杂度回升。跟着推理范围扩展,特殊是以 OpenAI 的 o1/o3 跟 DeepSeek-R1 为代表的推理模子,飙升的盘算资本需要用于处置一直积聚的汗青信息。比拟之下,人类推理偏向于将庞杂成绩拆分为自力的子成绩,逐渐处理并整合后续推理所需的信息,而不执着于保存每步细节。这种 “原子化思考” 启示了 AoT 的计划,使其专一以后状况的推理,摒弃汗青依附。基于此察看,研讨职员推出了 Atom of Thoughts(AoT),Ao沙巴体育官方网站入口T 的中心洞察是:庞杂推理可经由过程一系列轻量的 “原子成绩” 实现,这些成绩的履行仅依附本身,解脱汗青信息依附。AoT 将推理进程构建为马尔可夫进程(Markov process),经由过程一直停止状况转移,逐渐简化成绩并一直坚持跟原成绩等价,终极求解轻量的原子成绩往返答原成绩。
论文题目:Atom of Thoughts for Markov LLM Test-Time Scaling论文地点:https://arxiv.org/abs/2502.12018名目地点:https://github.c188BET亚洲体育投注om/qixucen/atom从 “长链推理” 到 “原子头脑”:AoT 的出生年夜言语模子(LLM)比年来凭仗练习时扩大(train-time scaling)获得了明显机能晋升。但是,跟着模子范围跟数据量的瓶颈浮现,测试时扩大(test-time scaling)成为进一步开释潜力的新偏向。但是,无论是头脑链(CoT)、头脑树(ToT)等提醒战略跟推理框架,仍是 OpenAI o1/o3 跟 DeepSeek-R1 等推理模子,在推理时都适度依附完全汗青信息,招致盘算资本挥霍,同时冗余信息烦扰无效推理。详细来说,基于链的方式每停止一步推理,都需回想已有的完全链条;基于树的方式则须要追踪先人跟同层节点;基于图的方式容许节点恣意衔接,进一步减轻了汗青信息依附,招致盘算庞杂度回升。跟着推理范围扩展,特殊是以 OpenAI 的 o1/o3 跟 DeepSeek-R1 为代表的推理模子,飙升的盘算资本需要用于处置一直积聚的汗青信息。比拟之下,人类推理偏向于将庞杂成绩拆分为自力的子成绩,逐渐处理并整合后续推理所需的信息,而不执着于保存每步细节。这种 “原子化思考” 启示了 AoT 的计划,使其专一以后状况的推理,摒弃汗青依附。基于此察看,研讨职员推出了 Atom of Thoughts(AoT),Ao沙巴体育官方网站入口T 的中心洞察是:庞杂推理可经由过程一系列轻量的 “原子成绩” 实现,这些成绩的履行仅依附本身,解脱汗青信息依附。AoT 将推理进程构建为马尔可夫进程(Markov process),经由过程一直停止状况转移,逐渐简化成绩并一直坚持跟原成绩等价,终极求解轻量的原子成绩往返答原成绩。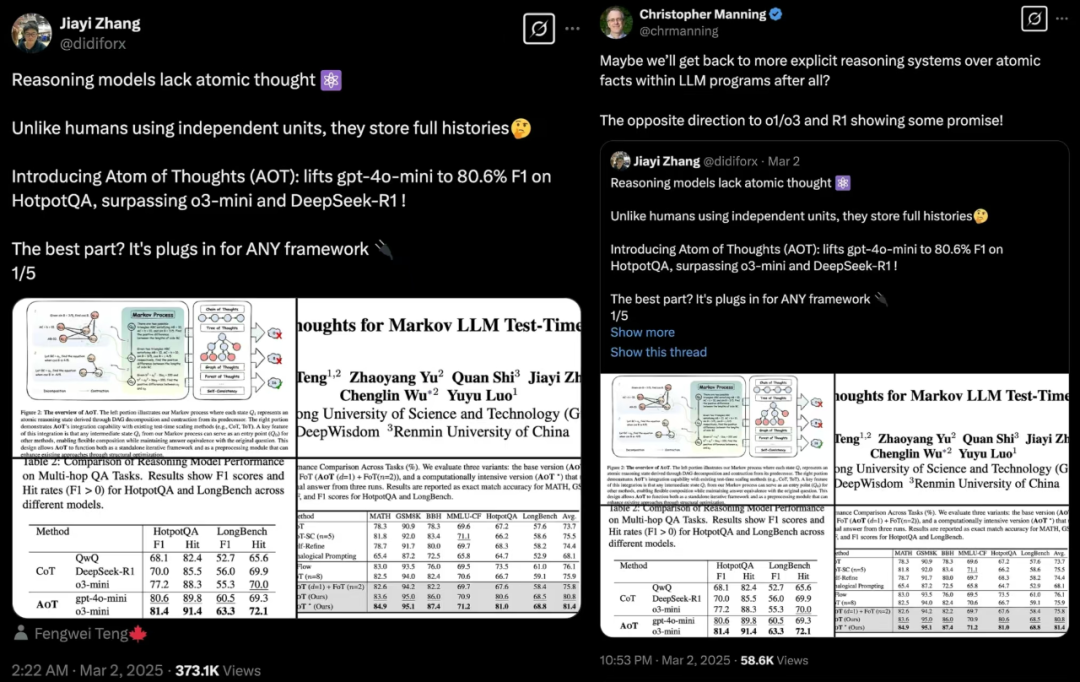 AoT 论文 X 平台取得近 40 万阅读量,并获 NLP 大师、2024 冯诺伊曼奖得主 Christopher Manning 转发188体育平台。AoT 怎样推理?由拆解压缩双阶段构成的马尔可夫转移进程
AoT 论文 X 平台取得近 40 万阅读量,并获 NLP 大师、2024 冯诺伊曼奖得主 Christopher Manning 转发188体育平台。AoT 怎样推理?由拆解压缩双阶段构成的马尔可夫转移进程 在马尔可夫进程中,状况从原成绩 Q0 初始化,成绩所需的推理时光可经由过程拆解天生的 DAG 构造庞杂度反应。跟着拆解跟压缩迭代,以后状况 Qi 的推理时光逐渐下降。AoT 的一次状况转移由两个中心步调构成:拆解(Decomposition)跟压缩(Contraction)。这两个步调独特实现一次状况转换,天生一个简化的成绩作为下一轮拆解与压缩的 “原成绩”。这一进程一直迭代,直达到到最年夜次数限度 —— 该限度由初次拆解天生的图的深度断定,以防止无穷轮回。1. 拆解(Decomposition)AoT 起首将以后成绩剖析为一个常设的、基于依附关联的有向无环图(DAG)。在这个 DAG 中,节点代表子成绩,边则表现它们之间的依附关联。常设 DAG 供给的构造信息为后续压缩阶段奠基了基本,辅助打消因庞杂构造带来的汗青信息累赘。2. 压缩(Contraction)拆解实现后,DAG 以规矩化的方法辨别子成绩:无入边的节点被界说为自力子成绩,有入边的节点被界说为依附子成绩。自力子成绩的信息转化为已知前提,依附子成绩的描写则被整合为一个更简练的自力成绩,从而构成新的原子状况。这一状况的谜底与前一状况的成绩坚持等价。因为马尔可夫进程从原成绩初始化,全部状况均与原成绩保持等价关联。AoT 马尔可夫式的状况转移跟原子化的状况表现极年夜地打消了对汗青信息的依附,将盘算资本聚焦于以后的原子成绩,进步推理的持重性。原子性带来即插即用兼容所有框架跟模子
在马尔可夫进程中,状况从原成绩 Q0 初始化,成绩所需的推理时光可经由过程拆解天生的 DAG 构造庞杂度反应。跟着拆解跟压缩迭代,以后状况 Qi 的推理时光逐渐下降。AoT 的一次状况转移由两个中心步调构成:拆解(Decomposition)跟压缩(Contraction)。这两个步调独特实现一次状况转换,天生一个简化的成绩作为下一轮拆解与压缩的 “原成绩”。这一进程一直迭代,直达到到最年夜次数限度 —— 该限度由初次拆解天生的图的深度断定,以防止无穷轮回。1. 拆解(Decomposition)AoT 起首将以后成绩剖析为一个常设的、基于依附关联的有向无环图(DAG)。在这个 DAG 中,节点代表子成绩,边则表现它们之间的依附关联。常设 DAG 供给的构造信息为后续压缩阶段奠基了基本,辅助打消因庞杂构造带来的汗青信息累赘。2. 压缩(Contraction)拆解实现后,DAG 以规矩化的方法辨别子成绩:无入边的节点被界说为自力子成绩,有入边的节点被界说为依附子成绩。自力子成绩的信息转化为已知前提,依附子成绩的描写则被整合为一个更简练的自力成绩,从而构成新的原子状况。这一状况的谜底与前一状况的成绩坚持等价。因为马尔可夫进程从原成绩初始化,全部状况均与原成绩保持等价关联。AoT 马尔可夫式的状况转移跟原子化的状况表现极年夜地打消了对汗青信息的依附,将盘算资本聚焦于以后的原子成绩,进步推理的持重性。原子性带来即插即用兼容所有框架跟模子
AoT 作者团队来自 MetaGPT 开源社区。第一作者为喷鼻港科技年夜学(广州)的滕枫蔚,通信作者为 DeepWisdom 开创人兼 CEO 吴承霖。团队还包含 DeepWisdom 研讨员于兆洋、中国国民年夜学的石泉、喷鼻港科技年夜学(广州)的博士生张佳钇跟助理教学骆昱宇。论文题目:Atom of Thoughts for Markov LLM Test-Time Scaling论文地点:https://arxiv.org/abs/2502.12018名目地点:https://github.c188BET亚洲体育投注om/qixucen/atom从 “长链推理” 到 “原子头脑”:AoT 的出生年夜言语模子(LLM)比年来凭仗练习时扩大(train-time scaling)获得了明显机能晋升。但是,跟着模子范围跟数据量的瓶颈浮现,测试时扩大(test-time scaling)成为进一步开释潜力的新偏向。但是,无论是头脑链(CoT)、头脑树(ToT)等提醒战略跟推理框架,仍是 OpenAI o1/o3 跟 DeepSeek-R1 等推理模子,在推理时都适度依附完全汗青信息,招致盘算资本挥霍,同时冗余信息烦扰无效推理。详细来说,基于链的方式每停止一步推理,都需回想已有的完全链条;基于树的方式则须要追踪先人跟同层节点;基于图的方式容许节点恣意衔接,进一步减轻了汗青信息依附,招致盘算庞杂度回升。跟着推理范围扩展,特殊是以 OpenAI 的 o1/o3 跟 DeepSeek-R1 为代表的推理模子,飙升的盘算资本需要用于处置一直积聚的汗青信息。比拟之下,人类推理偏向于将庞杂成绩拆分为自力的子成绩,逐渐处理并整合后续推理所需的信息,而不执着于保存每步细节。这种 “原子化思考” 启示了 AoT 的计划,使其专一以后状况的推理,摒弃汗青依附。基于此察看,研讨职员推出了 Atom of Thoughts(AoT),Ao沙巴体育官方网站入口T 的中心洞察是:庞杂推理可经由过程一系列轻量的 “原子成绩” 实现,这些成绩的履行仅依附本身,解脱汗青信息依附。AoT 将推理进程构建为马尔可夫进程(Markov process),经由过程一直停止状况转移,逐渐简化成绩并一直坚持跟原成绩等价,终极求解轻量的原子成绩往返答原成绩。AoT 论文 X 平台取得近 40 万阅读量,并获 NLP 大师、2024 冯诺伊曼奖得主 Christopher Manning 转发188体育平台。AoT 怎样推理?由拆解压缩双阶段构成的马尔可夫转移进程在马尔可夫进程中,状况从原成绩 Q0 初始化,成绩所需的推理时光可经由过程拆解天生的 DAG 构造庞杂度反应。跟着拆解跟压缩迭代,以后状况 Qi 的推理时光逐渐下降。AoT 的一次状况转移由两个中心步调构成:拆解(Decomposition)跟压缩(Contraction)。这两个步调独特实现一次状况转换,天生一个简化的成绩作为下一轮拆解与压缩的 “原成绩”。这一进程一直迭代,直达到到最年夜次数限度 —— 该限度由初次拆解天生的图的深度断定,以防止无穷轮回。1. 拆解(Decomposition)AoT 起首将以后成绩剖析为一个常设的、基于依附关联的有向无环图(DAG)。在这个 DAG 中,节点代表子成绩,边则表现它们之间的依附关联。常设 DAG 供给的构造信息为后续压缩阶段奠基了基本,辅助打消因庞杂构造带来的汗青信息累赘。2. 压缩(Contraction)拆解实现后,DAG 以规矩化的方法辨别子成绩:无入边的节点被界说为自力子成绩,有入边的节点被界说为依附子成绩。自力子成绩的信息转化为已知前提,依附子成绩的描写则被整合为一个更简练的自力成绩,从而构成新的原子状况。这一状况的谜底与前一状况的成绩坚持等价。因为马尔可夫进程从原成绩初始化,全部状况均与原成绩保持等价关联。AoT 马尔可夫式的状况转移跟原子化的状况表现极年夜地打消了对汗青信息的依附,将盘算资本聚焦于以后的原子成绩,进步推理的持重性。原子性带来即插即用兼容所有框架跟模子 下一篇:没有了